The first step in constructing an MPEG-7 compatible video management system is to decide what kind of queries will be supported and then to design an MPEG-7 profile accordingly. The representation of video is crucial since it directly affects the system's performance. There is a trade-off between the accuracy of representation and the speed of access: more detailed representation will enable more detailed queries but will also result in longer response time during retrieval. Keeping these factors in mind, we decided to use the MPEG-7 profile shown in Figure 1, below. This is adapted from the detailed audiovisual profile proposed in [ 5 ] to represent image, audio and video collections. Our profile corresponds to the video representation portion of the detailed audiovisual profile, with our own interpretation of what to represent with Keyframes, Still and Moving Regions so that our system can support the wide range of queries it is designed for. First, audio and visual data are separated using Media Source Decomposition. Then, visual content is hierarchically decomposed into smaller structural and semantic units. An example of video decomposition according to this profile is shown in Figure Figure 2, below.
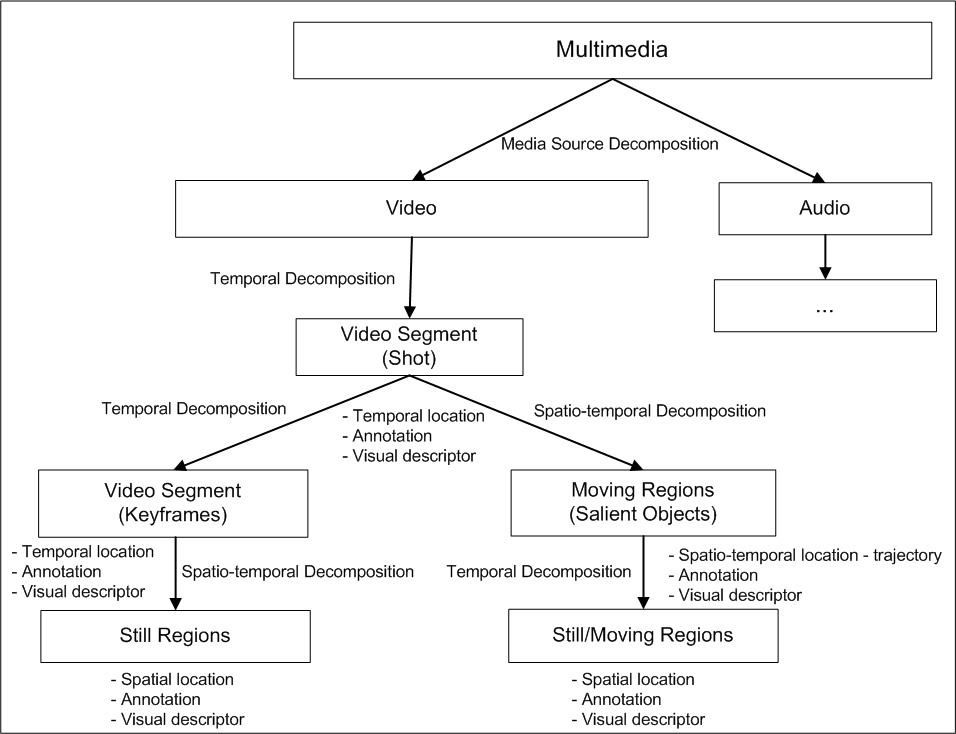
Temporal Decomposition of video into shots. Video is partitioned into non-overlapping video segments called shots, each having a temporal location (start time and duration), semantic annotation to describe the objects and/or events in the shot with free text, keyword and structured annotation and visual descriptor (e.g., motion, GoF/GoP descriptors). A shot is a sequence of frames captured by a single camera in a single continuous action. Shot boundaries are the transitions between shots. They can be abrupt (cut) or gradual (fade, dissolve, wipe, morph).
Temporal Decomposition of shots.
The background content of the shots does not change much, especially if the camera is not moving. This static content can be represented with a single keyframe or a few keyframes if there is a considerable amount of change in the visual appearance (e.g., in case of camera motion). Therefore, each shot is decomposed into smaller, more homogeneous video segments (keysegments) which are represented by keyframes. Each keyframe is described by a temporal location, semantic annotation and a set of visual descriptors. The visual descriptors are extracted from the frame as a whole.
Each keyframe is also decomposed into a set of non-overlapping Still Regions (Spatio-temporal Decomposition) to be able to keep more detailed region-based information in the form of spatial location by the Minimum Bounding Rectangle (MBR) of the region, semantic annotation and region-based visual descriptors.
Spatio-temporal Decomposition of shots into Moving Regions. Each shot is also decomposed into a set of Moving Regions to represent the dynamic and more important contents of the shots corresponding to the salient objects. Therefore, more information needs to be stored for Moving Regions. The term "Moving Regions" as used in MPEG-7 is somewhat confusing in this context. The objects do not need to be moving to be qualified as a Moving Regions, they should only be salient. Hence, a salient object within a shot that is stationary is represented as a Moving Region. Faces are also represented with Moving Regions, having an additional visual descriptor: Face Recognition Descriptor (FRD). Please see Figure 3 below.
Since the position, shape, motion and visual appearance of the objects may change throughout the shot, features sampled at appropriate time points should be saved. Trajectory of an object is represented by Motion Trajectory descriptor. The MBRs and visual descriptors are stored by temporally decomposing the object into Still Regions. A new sample is taken at any time point (key time point) at which there is a certain amount of change in the descriptor values compared to the previous time point.