Object Recognition as Machine Translation We propose a new approach to the
object recognition problem, motivated by the recent availability of
large annotated image collections. The correspondences between words
and image regions
are learned and then used to predict words corresponding to particular
image regions (region naming), or words associated with whole images
(auto-annotation).
Associating video frames with words Integration of visual and textual data is proposed to solve the correspondence problem between video frames and associated text in order to annotate video frames with more reliable labels and description |
|
 |
Face Recognition on the
Large Scale . |
 |
Retrieval and
Transcription of Ottoman Documents |
 |
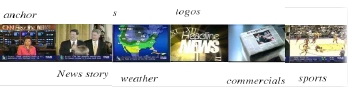
Tracking evolution of news in time In news videos, news stories are often accompanied by short video clips that tend to be repeated during the course of the event. Automatic detection of such repetitions is essential for creating auto-documentaries and understanding different perspectives. |
 |
Video
Analysis and Retrieval |
 |
IRIS: Information Retrieval as integration of Image and Semantics |
 |
Clustering Art Large online collections of images are attractive in principal, but in in practice they are difficult to use. Ideally one would be able to navigate a large image collection in a natural way. As a step towards this goal we proposed an image database browser based on the clusters obtained using both image features and text. |
 |
Form Document Processing We develop a logical representation for form documents and to use the representation for identification. A heuristic algorithm is presented to transform geometric structure of a form into a logical structure by using horizontal and vertical lines which exist on the form. The logical structure is represented by a hierarchical tree. Logically same forms will have the same hierarchical tree structure. Also, geometrical modifications and slight variations on a form are handled by the proposed representation. |