
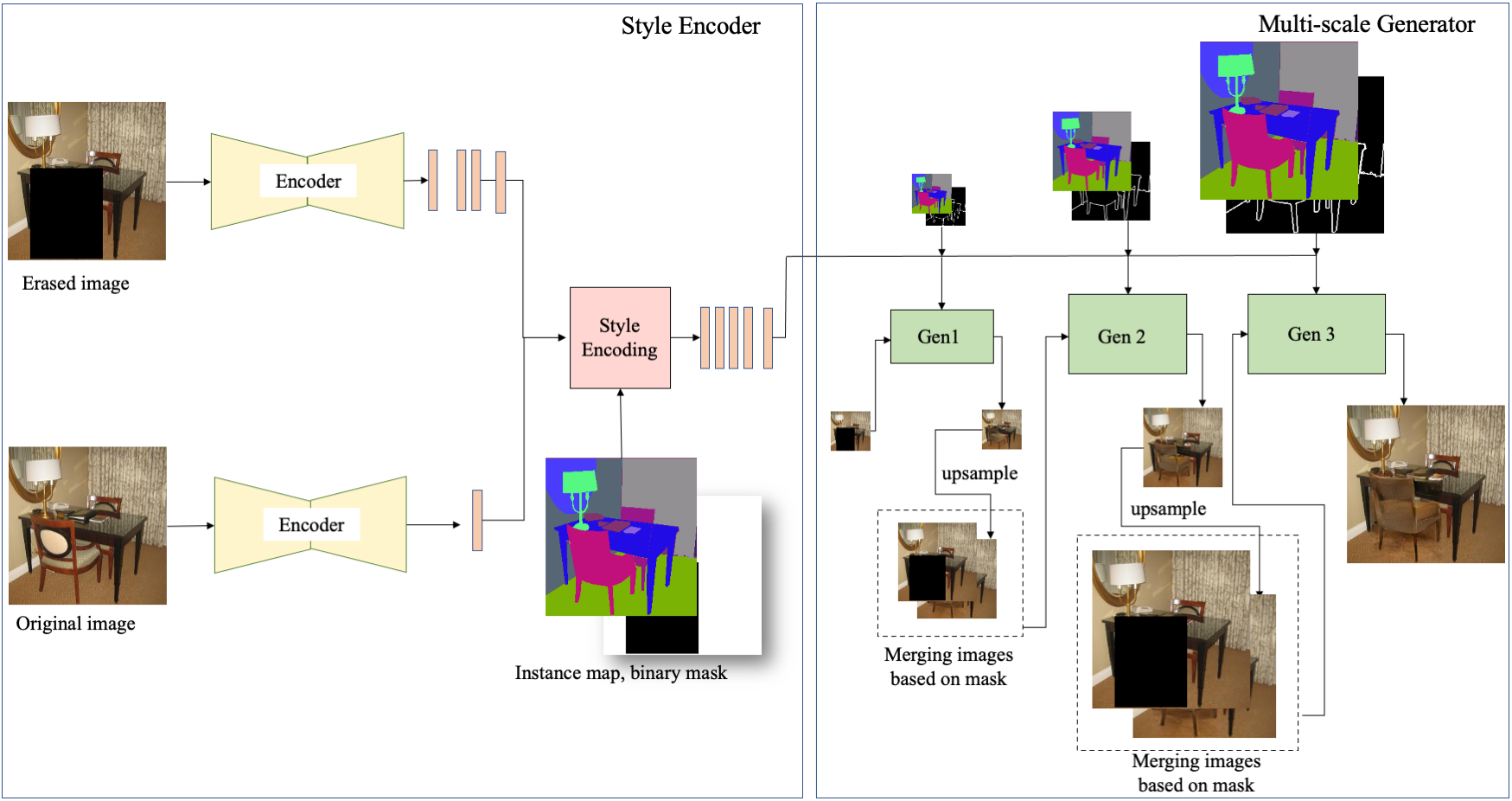
Results
Comparison with Other Models
DivSem ADE20k-room & ADE20k-landscape results and others
 Masked |
 SPADE |
 SEAN |
 SESAME |
 SPMPGAN |
 Ours |
 Masked |
 SPADE |
 SEAN |
 SESAME |
 SPMPGAN |
 Ours |
 Masked |
 SPADE |
 SEAN |
 SESAME |
 SPMPGAN |
 Ours |
DivSem Cityscapes results and others
 Masked |
 SPADE |
 SEAN |
 SESAME |
 SPMPGAN |
 SIEDOB |
 Ours |
 Masked |
 SPADE |
 SEAN |
 SESAME |
 SPMPGAN |
 SIEDOB |
 Ours |
Diverse Scene Editing

Panaroma Results
