Domain-Specific Language for Warehouse Robots & Its Lexical Analyzer
This semester's projects are about the design of a new language that is limited to programming warehause robots.
Language Overview. You will design a DSL for controlling autonomous warehouse robots on a 2D grid.
The DSL must express navigation, scanning, and item-handling actions in a clear and reliable way.
Warehouse Model & Assumptions
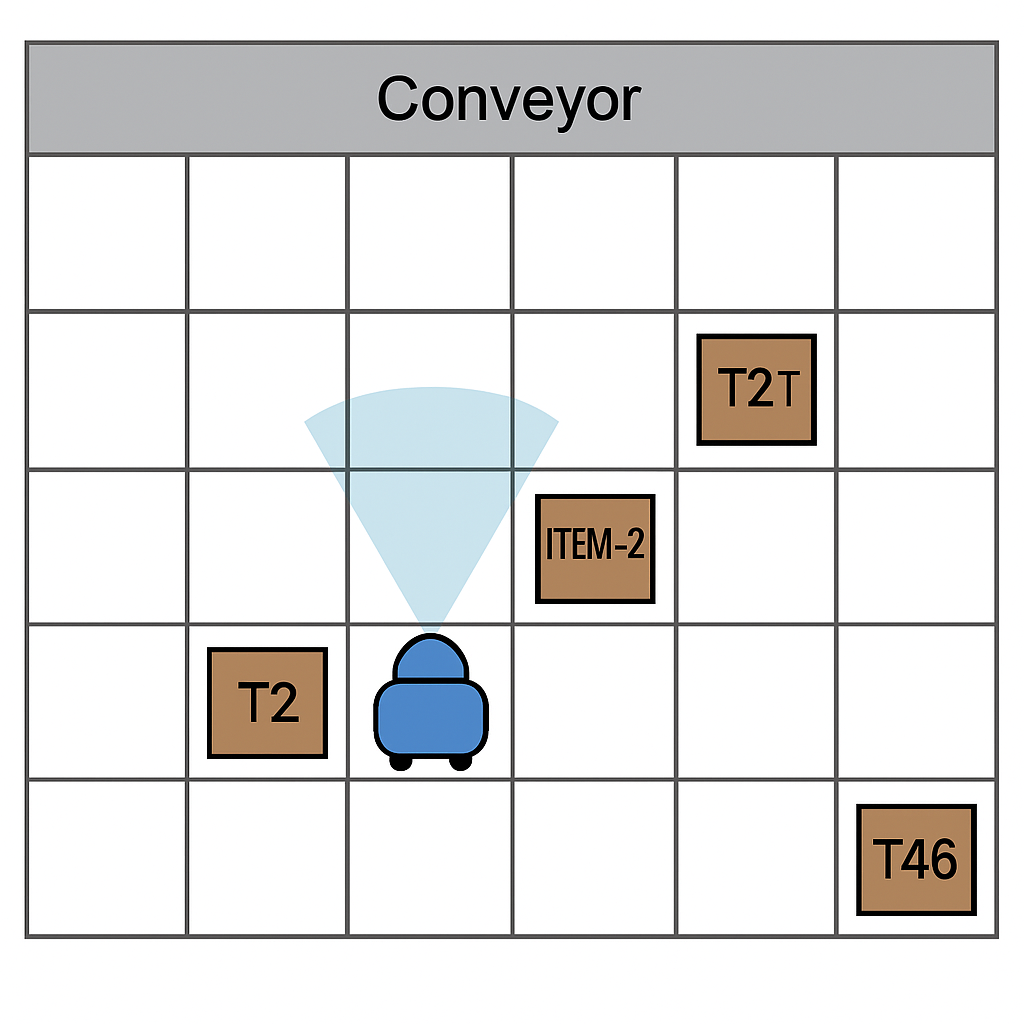
Grid: The warehouse is an n × m grid of 1×1 cells. One step moves to an adjacent cell in the direction of the heading.
Headings are {0, 90, 180, 270}. The program must setn and m at startup (see Required Built-ins).
Conveyor belt: The entire top row (row index n) is a conveyor belt. Belt cells are not traversable.
When the robot stands at row n-1 facing north, lift_down() places the carried item onto the conveyor.
Totes & items: Tote boxes are single-cell floor objects placed on random cells.
Some tote boxes carry an item with an ID label (e.g., ITEM-24).
Single-cell occupancy: Robot and each tote occupy exactly one cell; no two objects share a cell.
Program-managed pose: There is no absolute position sensor.
The program in this language may track the robot’s (row, col, heading) in variables, and update them on turns and successful moves.
Look-ahead:front_clear() returns whether the next cell is an empty floor cell (boolean).
Movement:move_forward() attempts to advance one cell and returns true on success, false if blocked (state unchanged).
move_backward() behaves analogously.
Pick/place:lift_up() picks the tote in the front cell if present (carrying=true; front cell becomes empty).
lift_down() places the carried tote to the front cell if it is an empty floor cell; or places the carried item to the conveyor belt when adjacent and facing north. lift_stop() is a no-op.
Scanning:scan() returns the visible ID string in the front cell with priority: item ID (if a tote with an item is in front),
else tote ID, else "".
The first part of the project is about the design of the language and the implementation of its lexical analyzer.
Part A - Language Design (30 points)
First, you will give a name to your language and design its syntax.
Note that the best way to hand in your design is with its grammar in the BNF (not EBNF) form,
followed by a description of each of your language components.
The following is a list of minimal features that are required in your language:
Function definitions (functions take any number of, and return a single, real values)
Comments.
You are encouraged to use your imagination to extend the list given above.
Discuss any other features of your language that you think is important.
Do not panic! You will have a chance to do minor revisions
to your syntax design for Project 2 (later in the semester).
Language designs are almost never exactly right in the first iteration.
Just try your best to make it as readable/writable/reliable as you
can and keep your eyes open for what does and what does not work :)
Part B - Lexical Analyzer (40 points)
Having designed the language, you will design and implement a lexical analyzer for your language,
using the lex tool available on all Unix-style systems.
Your scanner should read its input stream and output a sequence of tokens corresponding to
the lexemes you will define in your language.
Since at this stage, you will not be able to connect the output to a parser,
your scanner will print the names of the tokens on the screen.
For instance, if we were designing a C-like syntax, for the input
if (a - b) x <- 7.5 ; display "OK" x ;
the lexical analyzer should produce the output similar to the following:
IF LP IDENTIFIER OP IDENTIFIER RP IDENTIFIER ASSIGN CONST SC DISPLAY STR IDENTIFIER SC
For conditional statements, such as if, you may follow the convention in the C language, that is,
the value 0 is considered to be false and any non-zero value is considered to be true.
Part C - Example Programs (30 points)
Finally, you will prepare 3 test programs of your choice that
exercise all of the language constructs in your language, including
the ones that you may have defined in addition to the required list given
above. Be creative, and have some fun.
Additional to your test programs, write the programs for the following two programs given as pseudo-code:
Program 1: Search by Item ID: traverse the grid, use scan() to find a target item ID on a tote, and stop when found.
Program 2: Carry Task: pick the specific item from its tote in a source cell and carry it either to another empty floor cell or onto the conveyor belt (when adjacent).
Make sure your lex implementation correctly identifies all the tokens.
The TA will test your lexical analyzer with these example programs
along with other programs written in your language.
The test programs must be fully commented.
Do not panic! You are not required to write an interpreter
or compiler for this language. Just write a few programs in the
language you designed and make sure that the lexical analyzer produces
the right sequence of tokens.
Teams
The project will be implemented in teams of two or three students.
The members of the teams will be the same for this and the next project,
in which you will write a parser for your programming language.
Note that all members of a team will get the same grade in this part.
We will assume each member has contributed to the project equally.
Submission
There are several parts that you will hand in.
A project report including the following components:
Name, ID, and section for all of the project group members.
The name of your programming language.
The complete BNF description of your language.
About one paragraph explanation for each language construct
(i.e. variables and terminals) detailing their intended usage and meaning, as
well as all of the associated conventions.
Descriptions of how nontrivial tokens (comments, identifiers, literals, reserved words, etc)
are defined in your language. For all of these, explain what your motivations and
constraints were and how they relate to various language criteria
such as readability, writability, reliability, etc.
Your lex description file
The example program described above, written in your language
Make sure your lexical analyzer compiles and runs on dijkstra.cs.bilkent.edu.tr .
The TA will test your project on the dijkstra machine,
and any project that does not compile or run on this machine will get 0 on Part-B.
Your password is the same as the one for your @ug.bilkent.edu.tr e-mail account.
Please upload all of the above items, as a single zip file, to Moodle before the due date.
PDF format is preferred for the project reports.
Late submissions will be accepted, with 20 points (out of 100) deduction for each extra day.