Question: Given the following grammar,
<program> ::= <stmt_list>
<stmt_list> ::= <stmt> | <stmt> <stmt_list>
<stmt> ::= <declaration_stmt> | <assign_stmt>
<declaration_stmt> ::= var <ident_list> ;
<ident_list> ::= <var_id> | <var_id> , <ident_list>
<var_id> ::= a | b | c | d | e
<assign_stmt> ::= <var_id> = <expression> ;
<expression> ::= <expression> + <expression>
| <constant> | <var_id>
<constant> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
a) Drive the string "var a, b, c; a = a + b + 5;",
using the rightmost derivation to show that it is in the language.
b) Show its parse tree.
c) Is the grammar ambiguous or not?
Answer:
a) The leftmost derivation:
<program> ⇒ <stmt_list>
⇒ <stmt> <stmt_list>;
⇒ <stmt> <stmt>;
⇒ <stmt> <assign_stmt>;
⇒ <stmt> <var_id> = <expression> ;
⇒ <stmt> <var_id> = <expression> + <expression>> ;
⇒ <stmt> <var_id> = <expression> + <constant> ;
⇒ <stmt> <var_id> = <expression> + 5 ;
⇒ <stmt> <var_id> = <expression> + <expression> + 5 ;
⇒ <stmt> <var_id> = <expression> + <var_id> + 5 ;
⇒ <stmt> <var_id> = <expression> + b + 5 ;
⇒ <stmt> <var_id> = <var_id> + b + 5 ;
⇒ <stmt> <var_id> = a + b + 5 ;
⇒ <stmt> a = a + b + 5 ;
⇒ <declaration_stmt> a = a + b + 5 ;
⇒ var <ident_list> ; a = a + b + 5 ;
⇒ var <var_id> , <ident_list> ; a = a + b + 5 ;
⇒ var <var_id> , <var_id> , <ident_list> ; a = a + b + 5 ;
⇒ var <var_id> , <var_id> , <var_id ; a = a + b + 5 ;
⇒ var <var_id> , <var_id> , c ; a = a + b + 5 ;
⇒ var <var_id> , b , c ; a = a + b + 5 ;
⇒ var a , b , c ; a = a + b + 5 ; ✓
23 sentential forms.
b) The parse tree
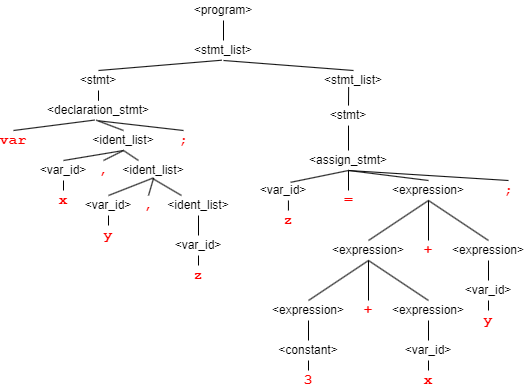
c) It is ambiguous,
becuase <expression> ::= <expression> + <expression> rule can be expanded from
the left <expression> or the right one leading to two different parse trees.
Question: Write a lex file to generate a scanner that will print EU_DATE or USA_DATE, if the input is a string representing a date in European or United States format, respectively. For other strings, it will display NOT_A_DATE.
You may assume the year value is grater than 1000, less than 10000.
Examples of USA date format: 2/19/2019, 10/29/1923, 04/20/1920, 1.2.2025.
Examples of EU date format: 19.2.2019, 29.10.1923, 20.04.2019, 2/1/2025.
Answer:
%option main
day 0?[1-9]|[12][0-9]|3[0-1]
month 0?[1-9]|1[0-2]
year [1-9][0-9][0-9][0-9]
%%
{month}\/{day}\/{year} printf("USA_DATE");
{day}\.{month}\/{year} printf("EU_DATE");
.* printf("NOT_A_DATE");
Question: In this quiz, you will write a yacc specification file with tokens corresponding to the unique letters in your first name, only. For example, in my case, the tokens are H, A, L, I.
a) Write the grammar rules in such a way that the grammar will have a shift/reduce conflict if your ID is odd, a reduce/reduce conflict if your ID is even.
b) Indicate on what token the conflict will occur.
c) Is your grammar ambiguous? Why?
Answer:
a) Shift/reduce conflict:
%token H A L I %% start: x L | y A I; x: H A; y: H ;
b) The token causing the conflict is A
c) The grammar is unambiguous. The language of the grammar is L={HAL, HAI}. Each of the words in the language has exactly one poarse tree.
start start
/ \ / | \
x L y A I
/ \ |
H A H
Or,
a) Reduce/reduce conflict:
%token H A L I %% start: x A L | y A I; x: H ; y: H ;
b) The token causing the conflict is A
c) The grammar is unambiguous. The language of the grammar is L={HAL, HAI}. Each of the words in the language has exactly one poarse tree.
start start
/ | \ / | \
x A L y A I
| |
H H
Question:
<script>
x = 5;
function foo() {
console.log("in foo 1, x=" + x);
x = 7; // (*)
console.log("in foo 2, x=" + x);
}
console.log("in global 1, x=" + x);
foo();
console.log("in global 2, x=" + x);
</script>
a) as given above.
b) when the line with (*) is replaced with
var x = 3;
c) when the line with (*) is replaced with
let x = 3;
Answer:
a)
The statement x = 3; is executed as an assignment to the global variable x.
The following are written to the console.log. Test the code
in global 1, x=5 in foo 1, x=5 in foo 2, x=7 in global 2, x=7
b)
The statement var x = 3; declares a new local variable x and
initializes it to undefined, as the first executable statement in the body of foo.
The console.log("in foo 1, x=" + x); statement displays that x is undefined.
The following are written to the console.log. Test the code
in global 1, x=5 in foo 1, x=undefined in foo 2, x=3 in global 2, x=5
c)
The statement let x = 3; declares a new local variable x
as the first executable statement in the body of foo,
but it does not initialize x.
The console.log("in foo 1, x=" + x); statement generates and error message indicating that x is not initialized>,
and the execution halts.
The following are written to the console.log. Test the code
in global 1, x=5
Uncaught ReferenceError: Cannot access 'x' before initialization
at foo (q4c.htm:7:32)
at q4c.htm:13:1
Question: What is the output of the following Perl program?
sub fun1 {
local $a = 10; # Replace 10 with the last digit of your ID
local $b = 20; # replace 20 with the second last digit of your ID
sub fun1_1 {
local $b = 30; # replace 30 with the last two digits of your ID
print "Point1_1: a=$a, b=$b\n";
fun1_2();
}
sub fun1_2 {
local $a = 44;
print "Point1_2: a=$a, b=$b\n";
fun2();
}
fun1_1();
print "Point1: a=$a, b=$b\n";
}
sub fun2 {
$a = 55;
print "Point2: a=$a, b=$b\n";
}
fun1();
print "Point3: a=$a, b=$b\n";
Answer: Assume the last two digits of your ID are X and Y.
Point1_1: a=Y, b=XY Point1_2: a=44, b=XY Point2: a=55, b=XY Point1: a=Y, b=X Point3: a=, b=
Question:
1) Consider the following Python code:
x = 3
def f(a):
global x
x = x + a
return x
y = f(x) + f(x)
print(y, x)
b) Briefly explain how operand evaluation order affects the result.
2) Consider the following JavaScript code:
function h(A, i) {
A[i] = A[i] + 1;
return A[i];
}
B = [10, 20];
let r = h(B, 0) - h(B, 0);
console.log(r, B);
b) Explain how operand evaluation order influences the result.
Answer:
1)
a) The output is: 18 12
b) Python evaluates operands left-to-right.
Execution:
First f(x) → f(3) › updates x to 6 → returns 6
Second f(x) → now x is 6 → f(6) → updates x to 12 → returns 12
y = 6 + 12 = 18
2)
a) The output is: -1 [12, 20]
b) JavaScript evaluates operands left-to-right.
Execution:
First call: B[0] becomes 11 → A[0] is 11 → function h() returns 11
Second call: B[0] becomes 12 → A[0] is 12 → returns 12
r = 11 - 12 = -1
B = [12, 20]
Question:
1) What is the parameter passing method used in Python?
2) What is the output of the following Python program?
def foo1(f):
f[0]=11
print("In foo1: ",f)
a = ['a','b','c']
foo1(a)
print("After foo1: ",a)
def foo2(f):
f = f + (22,23)
print ("In foo2: ",f)
a = (20,21)
foo2(a)
print("After foo2: ",a)
def foo3(f):
f['k4']=44
print ("In foo3: ",f)
a = {'k0':40,'k1':41}
foo3(a)
print("After foo3: ", a)
Answer:
1)Python uses pass-by-assignment parameter passimg method.
2) The output:
In foo1: [11, 'b', 'c']
After foo1: [11, 'b', 'c']
In foo2: (20, 21, 22, 23)
After foo2: (20, 21)
In foo3: {'k0': 40, 'k1': 41, 'k4': 44}
After foo3: {'k0': 40, 'k1': 41, 'k4': 44}
Question: What are the results of evaluating the following s-expressions, written in Scheme?
a) (cdr '(a b c d))
b) (null? (cddr '(a b)))
c) (list? (cddr '(a b)))
d) ((lambda (x y) (* x (/ x y))) 2 7)
e) (eq? (car '(a b)) (car '(a b c)))
f) (member 'b '((a b c)))
g) (append '(a b) (cdr '(a b)))
h) (apply cadr '((a b c d e)))
i) (map (lambda (n m) (+ n (* 2 m))) '(3 5) '(2 4))
j) (apply * (map car '((3 5) (2 7) (4))))
Answer:
a) (b c d))
b) #t
c) #t
d) 4/7
e) #t
f) #f
g) (a b b)
h) b
i) (7 13)
j) 24